Building DAGs
This guide explains how to create and organize Directed Acyclic Graphs (DAGs) in Cyclonetix. A DAG is a collection of tasks with dependencies that form a workflow.
DAG Definition
In Cyclonetix, you can define DAGs explicitly using YAML files. Here’s the basic structure:
id: "dag_id" # Unique identifier for the DAG
name: "Human-readable name" # Display name
description: "DAG description" # Optional description
tasks: # List of tasks to include
- id: "task_1"
- id: "task_2"
- id: "task_3"
tags: ["tag1", "tag2"] # Optional categorization tagsDAG File Organization
DAG definitions are typically stored in the data/dags directory:
data/
└── dags/
├── etl_pipeline.yaml
├── ml_training.yaml
└── model_deployment.yamlIncluding Tasks in a DAG
The tasks section lists all tasks that should be included in the DAG:
tasks:
- id: "data_extraction"
- id: "data_transformation"
- id: "data_loading"
- id: "data_validation"Each task in the list must have a corresponding task definition file in the tasks directory.
Task Dependencies
When you include tasks in a DAG, Cyclonetix automatically respects the dependencies defined in each task. You don’t need to redefine the dependencies in the DAG file.
For example, if data_transformation depends on data_extraction in their task definitions, this dependency will be automatically respected when you include both tasks in your DAG.
Parameter Overrides
You can override default task parameters at the DAG level:
tasks:
- id: "data_extraction"
parameters:
source: "production_db"
limit: 1000
- id: "data_transformation"
parameters:
mode: "full"These overrides take precedence over the default values defined in task files.
Context Assignment
You can assign a specific context to a DAG:
id: "etl_pipeline"
name: "ETL Pipeline"
context: "production"
tasks:
- id: "data_extraction"
- id: "data_transformation"
- id: "data_loading"The specified context will be used for all tasks in the DAG, providing shared environment variables and configuration.
Scheduling Configuration
DAGs can include scheduling information:
id: "daily_report"
name: "Daily Reporting Pipeline"
schedule:
cron: "0 5 * * *" # Run daily at 5:00 AM
timezone: "UTC"
catchup: false # Don't run missed executions
tasks:
- id: "generate_report"
- id: "send_email"Nested DAGs
You can include other DAGs as components of a larger DAG:
id: "end_to_end_pipeline"
name: "End-to-End Data Pipeline"
dags:
- id: "data_ingestion"
- id: "data_processing"
- id: "reporting"
tasks:
- id: "final_notification"Nested DAGs maintain their internal dependencies while also respecting dependencies between DAGs.
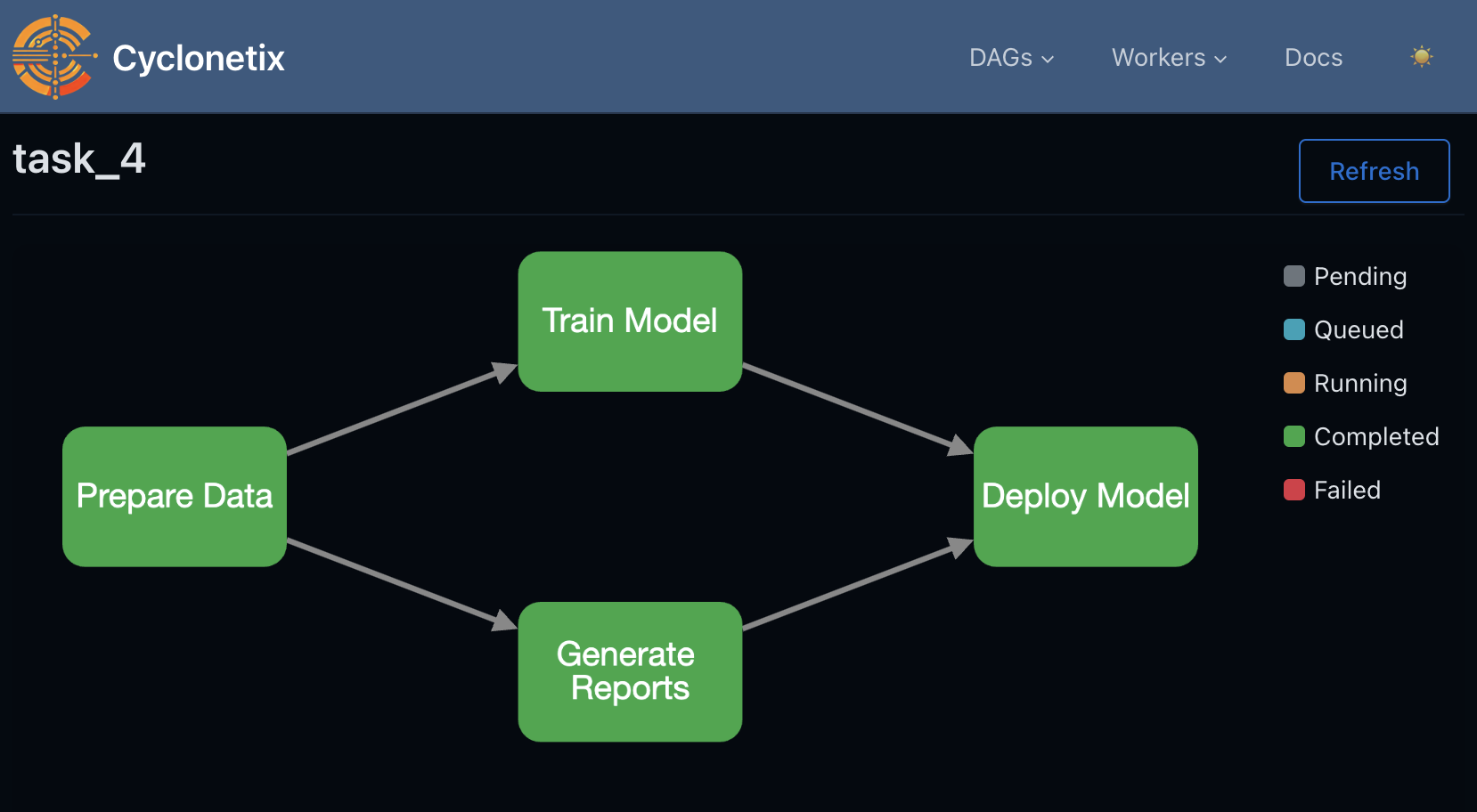
Visualizing DAGs
Once defined, you can visualize your DAG structure in the Cyclonetix UI:
- Navigate to the DAGs page in the UI
- Select the DAG you want to visualize
- View the graphical representation showing tasks and dependencies
Complete DAG Example
Here’s a comprehensive example of a DAG definition:
id: "ml_training_pipeline"
name: "ML Training Pipeline"
description: "Complete pipeline for training and evaluating ML models"
context: "ml_training"
schedule:
cron: "0 1 * * 0" # Weekly on Sunday at 1:00 AM
timezone: "UTC"
catchup: false
tasks:
- id: "data_extraction"
parameters:
source: "production_db"
tables: ["users", "transactions", "products"]
- id: "data_cleaning"
parameters:
mode: "strict"
- id: "feature_engineering"
parameters:
features_config: "/configs/features_v2.json"
- id: "train_model"
parameters:
model_type: "gradient_boosting"
hyperparams_file: "/configs/hyperparams.json"
- id: "evaluate_model"
parameters:
metrics: ["accuracy", "precision", "recall", "f1"]
- id: "register_model"
parameters:
registry: "mlflow"
model_name: "transaction_classifier"
tags: ["ml", "production", "weekly"]Next Steps
- Learn about Scheduling Workflows
- Understand UI Overview
- Explore Contexts & Parameters for more advanced configurations